What Is the Reading Level of the Neo-4
Neo4j vs GRAKN Part I: Basics
An exhaustive comparison between two most pop knowledge bases
![]()
Dear readers, in this series of articles I compared two pop noesis bases: Neo4j and Grakn. I decided to write this comparing long fourth dimension ago upon your requests, even so kismet is for now 😊
This is a detailed comparing in three parts: first part is devoted to technical details, the 2nd part dives into details of semantics and modeling. The introduction parts give quick data about how Neo4j and Grakn works, too as some details of what those bring us new. If you already know about the first parts, you can directly swoop into the semantic power part. The third part is devoted to comparison of graph algorithms, core of recommender systems and social networks. The series will continue with graph learning, chatbot NLU and more semantics with both platforms.
In this commodity, I will briefly compare how Neo4j mode of doing is unlike from Grakn way of doing things. As you will follow the examples of how to create a schema, how to insert, delete and query; you will discover the prototype difference. This part is not a battle, rather a comparison.
I know you cannot wait for the content, permit the comparing begin … here are some highlights:
How Grakn Works
Grakn is the knowledge graph, Graql is the query language notes Grakn homepage. Grakn is a knowledge graph, completely true; but the language Graql is data oriented and ontology like. Graql is declarative, one both defines information and manipulates data. We volition come across more on Graql in the next sections.
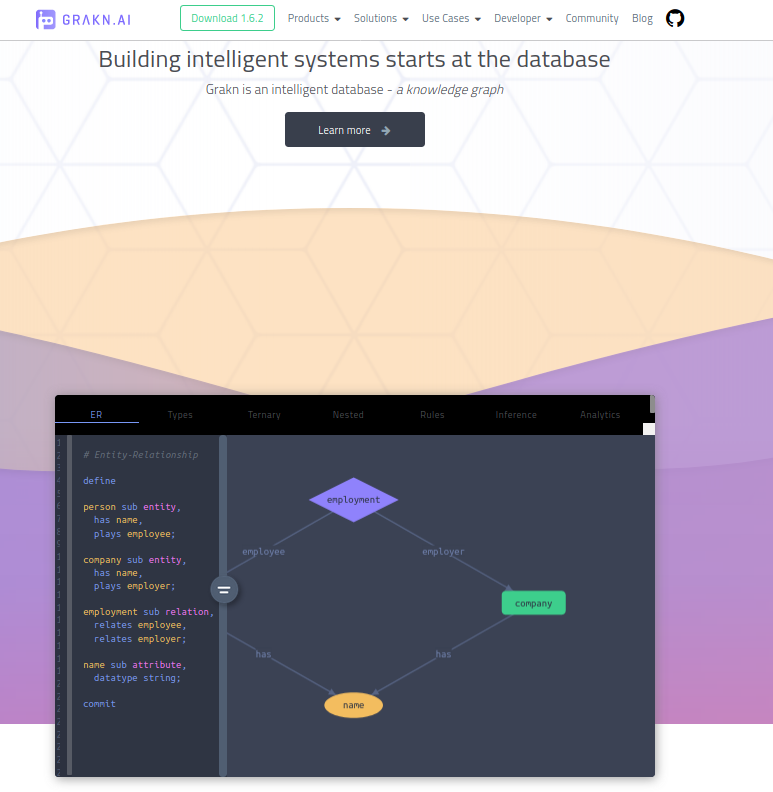
In my opinion Grakn is a knowledge base of operations, Graql is an data oriented query language; all these built onto a graph data construction but you never feel the graph is at that place. This is how information technology is described in their website:
When writing Graql queries, we merely draw what data we would like to recollect, rather than how should it be obtained. In one case nosotros specify the target information to retrieve, the Graql query processor volition take care of finding an optimal way to call up it. When I beginning met Grakn, I thought this is a cognition modeler and still I experience the same. Best explanation of what Grakn indeed is comes from themselves:
Grakn is a database in the grade of a cognition graph, that uses an intuitive ontology to model extremely complex datasets. It stores data in a way that allows machines to understand the meaning of data in the consummate context of their relationships. Consequently, Grakn allows computers to procedure complex data more intelligently with less homo intervention Graql is a declarative, cognition-oriented graph query linguistic communication that uses machine reasoning for retrieving explicitly stored and implicitly derived knowledge from Grakn.
As I said before, even though themselves said Grakn is a database , I however raise my objections and insist that Grakn is a cognition base 😄
How Neo4j Works
Neo4j is a graph-looking knowledge graph 😄 Though in their dwelling house page I meet the connected data once, one has to go through their documentation to see the semantics they actually bring:
Although they wrote simply a graph database in their front page, I highly disagree. Neo4j is a knowledge graph definitely. One can meet relations, classes, instances, properties i.e. the schema definition. This is semantics, that's it. Neo4j definitely is not simply a graph database, 1 can model the knowledge.
How Grakn Wins over OWL
OK if we already can write down some OWL then, why should nosotros use Grakn instead, one might call up. Grakn explained this upshot in their mail service in detail. For me, first plus is definitely Graql, easy to read and write. OWL is usually created by Protégé or other similar frameworks, the resulting XML is basically unreadable. Below find the same descends relationship in OWL-XML and Graql:
From the view of product, Grakn is
- scalable
- highly efficient
- has Python, Java, Node.js clients
- decently wrapped up as the whole framework
… i.eastward. production ready. From the view of development
- queries are highly optimized
- underlying information structure is flexible for semantic modeling
- graph algorithms are also provided.
From the view of semantics, Grakn has more power; the data model
- is easy to update/add onto
- allows abstruse types (we will come up to this)
- has a huge plus over OWL, it guarantees logical integrity. OWL has an open world supposition, whereas Grakn offers a chichi combination of open earth and closed earth assumptions. You can read more about this at Logical Integrity section.
- allows more than brainchild details in full general. For case the underlying hypergraph allows n-ary relations. It'south a bit painful to model n-ary relations in OWL, there is a whole description here.
What Neo4j Brings
Honestly I don't know where to showtime. Neo4j shines in NoSQL world with providing connected data, shines among graph databases with his superior back end and high operation. Different many other graph databases, Neo4j offers
- fast reads and writes
- high availability
- horizontal scaling. Horizontal scaling is provided through 2 types of clustering: high availability clustering and causal clustering.
- cache sharding
- multiclustering
- no joins. Information is continued via edges, circuitous joins is not necessary to retrieve connected/related data
- granular security.
Personally I fell from my chair while reading Neo4j's unmatched scalability skills. I highly recommend visiting the corresponding folio. Warning: you may fall in love as well ❤️
From data perspective Neo4j offers
- temporal information support
- 3D spatial information support
- existent-fourth dimension analytics .
If you desire to model a social network, build a recommendation system or model connected information for any other task; yous desire to dispense temporal or spatial data, you desire a scalable, high functioning, secure application the selection is Neo4j. No more words here.
Getting Started
Getting started with Grakn is easy: start one installs the Grakn, then make a grakn server start . Afterward, 1 either can work with Grakn panel or Grakn workbase .
Aforementioned applies to Neo4j, download and install is provided in a very professional style. If you demand, Docker configuration and framework configuration manuals are in that location as well. Afterwards, you can download Neo4j browser and commencement playing or yous tin can discover the back end more. You can also experiment with Neo4j without downloading via their Sandbox which I really really liked. You tin can play around without whatsoever download hustle.
I must say I totally brutal in love with Neo4j documentation every bit a side annotation, level of attempt and professionalism is huge.
Development Surroundings and Visualization
Both Grakn and Neo4j offers IDEs for easy utilize and visualization.
Grakn workbase offers two functionalities: visualization of your knowledge graph and an easy way to interact with your schema. You can perform match-get queries and brand path queries inside the workbase.
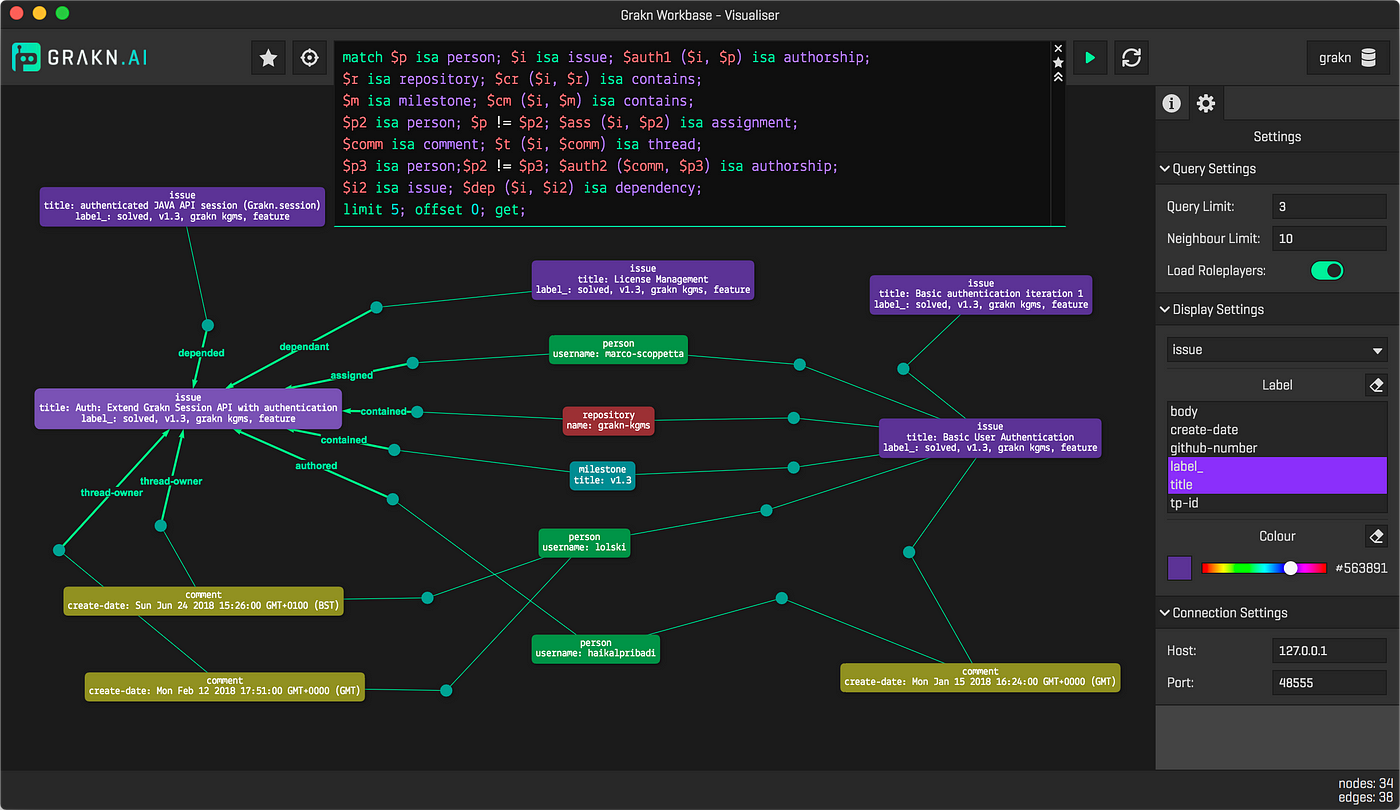
Neo4j offers their browser for two purposes besides: easy interaction and visualization. Ane can also explore patterns, clusters, and traversals in their graph.
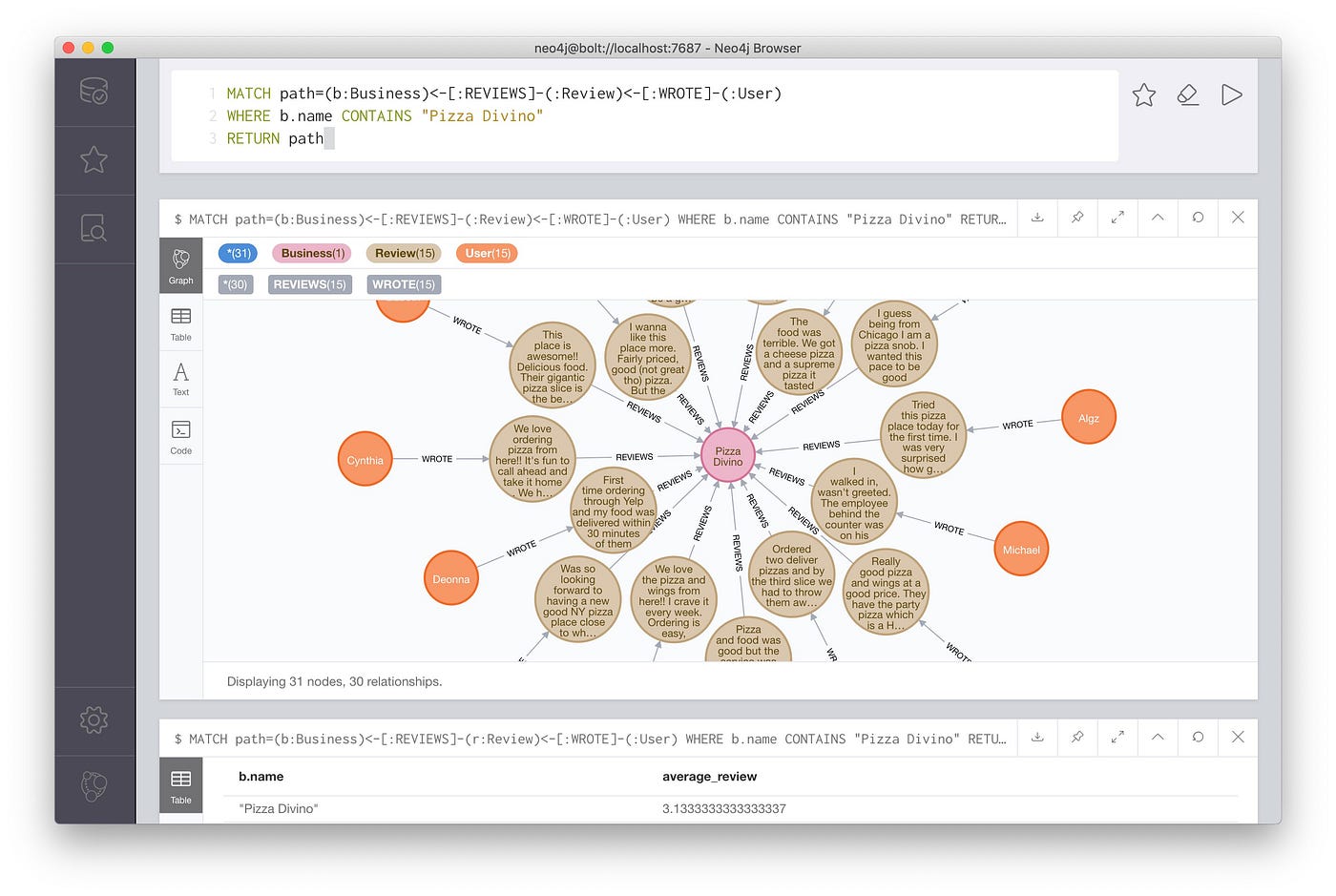
Moreover, Neo4j offering much more for visualization Neo4j Flower and other developer tools for visualization, mainly JS integration. With Neo4j Bloom one tin can find the clusters, patterns and more.
Information technology does non terminate here, Neo4j has fifty-fifty more visualization tools for spatial data and 3D. Neo4j is a primary of spatial data in general, simply visualization tools carry Neo4j to a different level:
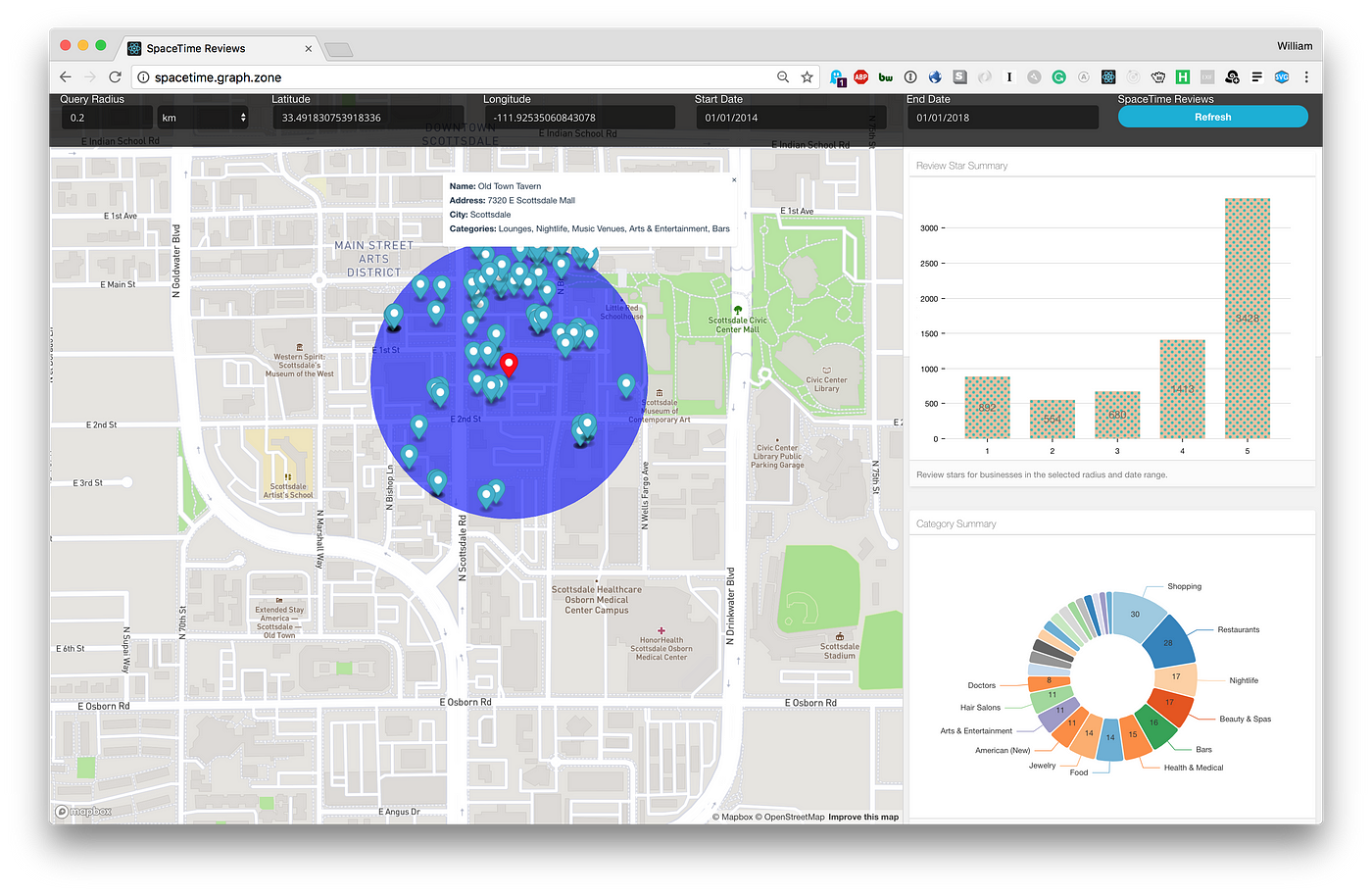
Both platforms offer great visualization, Neo4j offers more due to being older 😄
Nosotros covered basics of the both platforms, at present we tin can move onto development details.
Underlying Data Structure
For short Grakn is a hypergraph, Neo4j is a directed graph. If you are further interested how Neo4j stores his nodes, relations and attributes yous tin visit their developer manual or Stack overflow questions.
Data Modeling
Information modeling is the way we know from skilful onetime OWL.
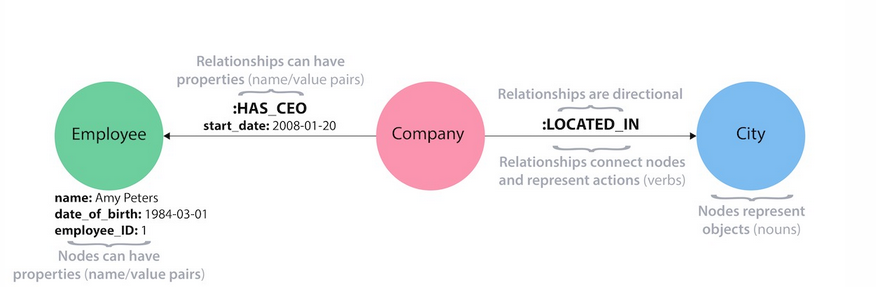
Neo4j works with cognition graph notions: nodes (instance), labels (form), relationships, human relationship types (attributes) and properties (information attributes).
Grakn style knowledge modeling is closer to ontology ways, declarative and more semantics oriented. Notions are:
- entities (classes)
- instances
- attributes
- roles
- rules
- blazon hierarchies
- abstruse types
If you are more onto the ontology side, Grakn manner of thinking is really similar. Modeling like shooting fish in a barrel, providing semantic power and efficient.
Query Language
Graql is declarative and more than data oriented. Neo4j's Zero is also declarative, however flavour is SQL. For me, Graql feels similar ontology, Cypher feels similar database query. Compare the post-obit simple queries in both languages:
//Nix MATCH (p:Person { proper noun: "Duygu" })
RETURN p //Graql
match
$p isa person, has name "Duygu";
get $p;
Personally I find Graql more semantics friendly.
Creating a Schema
Creating a schema in Grakn is easy, remember Graql is declarative. Basically you open a .gql file and start creating your schema, that'southward it 😄. Hither is an example from their front end folio:
defineperson sub entity,
has name,
plays employee;
company sub entity,
has name,
plays employer;
employment sub relation,
relates employee,
relates employer;
name sub attribute,
datatype cord;
Neo4j way of creation of entities and instances is CREATE . Once those ones are created, and so one tin can brand a MATCH query to go the respective nodes and create a relationship between them. 1 creates the nodes, edges and their attributes:
CREATE (d:Person { name:"Duygu"})
CREATE (thousand:Company {name: "German Autolabs"}) Lucifer (a:Person),(b:Company)
WHERE a.proper noun = 'Duygu' AND b.name = 'German Autolabs'
CREATE (a)-[r:Employed { since: '2018' }]->(b)
Render type(r), r.proper name
Querying
Graql is declarative, querying is in ontology fashion again. Querying is done by lucifer clauses. Here are some elementary queries nigh customers of a bank:
match $p isa customer; get; match $p isa customer, has start-name "Rebecca"; go; lucifer $p isa customer, has total-name $fn; { $fn contains "Rebecca"; } or { $fn contains "Michell"; }; get;
So far so good. At present, we tin can get some insights from our customers. This is a query for average debt of the Mastercard possessor customers, who are younger than 25 :
friction match
$person isa client, has age < 25;
$bill of fare isa credit-card, has type "Mastercard";
(client: $person, credit-card: $menu) isa contract, has debt $debt;
go $debt; mean $debt; Looks make clean. How about Neo4j? Aught querying is done by Lucifer clause as well, but with a completely different syntax; rather a database match flavor with a WHERE. When there is a WHERE , you can play some string method games equally well😄:
MATCH (client:Customer)
Return customer Friction match (client:Customer)
WHERE customer.first_name = 'Rebecca'
RETURN customer //or equivalently with a bit syntactic sugar Lucifer (customer:Customer {first_name: "Rebecca"})
RETURN customer // Friction match (customer:Customer)
WHERE p.first_name STARTS WITH 'Steph'
Return p
Coming to the relations, ane needs to go on an eye on the border direction via arrows. Here is a query for the bank customers who drives an Audi; notice the DRIVES relation is directed from customer to their machine:
Match (car:Car {brand: "Audi"})<-[:DRIVES]-(customers)
Return customers.first_name Aggregation is similar to SQL too, here is the aforementioned query for the young Mastercard user customers' debt:
Lucifer (customer:Client)-[:OWNS]->(carte:CreditCard {type: "Mastercard"})
WHERE customer.age < 25
RETURN AVG(carte.debt) SQL syntax applies to Cypher queries in full general, if you like to write SQL and then definitely y'all feel at abode with Cypher. This is a query for finding the node with most properties:
MATCH (n)
Return labels(n), keys(n), size(keys(n)), count(*)
Guild BY size(keys(n)) DESC Coming back to semantics, 1 can query how to entities/instances related:
MATCH (:Person { proper noun: "Oliver Stone" })-[r]->(movie)
Return blazon(r) //DIRECTED What about "joins" i.e. queries about related nodes? One normally handles such queries merely every bit in Grakn counterpart, just a bit more instances and more relation arrows:
//Proper name of the movies that Charlee Sheen acted and their directors MATCH (charlie { name: 'Charlie Sheen' })-[:ACTED_IN]->(movie)<-[:DIRECTED]-(manager)
RETURN movie.title, managing director.name
Time to time I emphasized Neo4j being a graphie graph, now allow's see information technology on action … One can make path queries with Nothing, or usual semantic queries with path restrictions .
Allow's say you have a social network and you would like to detect all persons who is related to Alicia in a altitude of 2 and who follows who in which direction is not important:
MATCH (p1:Person)-[:FOLLOWS*1..2]-(p2:Person)
WHERE p1.name = "Alicia"
Render p1, p2 Of course shortest path is a classic in social networks, you might want to know how close Alicia and Amerie are socially linked:
Friction match p = shortestPath((p1:Person)-[*]-(p2:Person))
WHERE p1.proper name = "Alicia" AND p2.name = 'Amerie'
RETURN p This mode nosotros look for the shortest path via any relation blazon. If we want we tin can replace [*] with [:FOLLOWS] to specify we desire this relation. (At that place might be other relation types attending the same higher, living in the same urban center…)
Every bit you lot see Cypher offers much more meets the heart. It is true that the syntax looks similar SQL … but story is very different, graph concepts and semantic concepts meet to fuel upwards Neo4j.
Inference
Semantic reasoners exist since RDF times. Inferring new relations and facts from schema knowledge and already existing data is easy for homo encephalon, just not so straightforward for the noesis base systems. Are nosotros allowing open up-world assumptions(if you lot practice non know sth for sure it does not mean it is incorrect, you only do not know); does world consist of what nosotros already know (what happens and then an unseen entity comes to our airtight-world), how much should we infer, should we allow long paths … Hermit was a pop choice for OWL (I used it as well) and information technology tin can be used as a plugin in Protégé.
Inference in Neo4j does not have born tool. Here I will introduce how Grakn tackles it.
Inference in Grakn is handled via rules . Hither is how they described what a rule is:
Grakn is capable of reasoning over information via pre-defined rules. Graql rules look for a given design in the dataset and when plant, create the given queryable relation. Graql reasoning is performed at query time and is guaranteed to be complete.
Let'due south run across an instance of a sibling rule, if two person has same mother and father; and then one can deduce they are siblings. How to express this inference in Grakn is as follows:

Grakn rule creation is intuitive: when some weather condition are met, and then we should infer the post-obit fact. I found the syntax refreshing and sweet. Especially in drug discovery and any other sort of discovery tasks i needs reasoning %100. If I was involved in discovery blazon tasks, I would use Grakn only for this reason.
Logical Integrity
Once you create your schema and tin can infer new relations, after that you would like your schema to stay intact and do non allow incorrect data to become into your model. For case, y'all would non desire to allow a marriage relation betwixt a person and a carpeting (though person + tree is legal in some parts of the earth😄).
Though Neo4j has constraints on their documentation, those are just database conventions for information validation and null checks:
Neo4j helps enforce data integrity with the use of constraints. Constraints can be practical to either nodes or relationships. Unique node belongings constraints can be created, too as node and relationship property beingness constraints. Graql ensures the logical integrity via roles , each part comes from a grade as you come across in above examples. Again, mandatory for discovery type tasks.
Scalability
Both are super scalable. I spoke a lot about Neo4j scalability to a higher place merely kept Grakn way of scalability as a surreptitious 😄 Grakn leverages Cassandra under the hood, hence Grakn is enjoys being strongly consistent, scalable and fault tolerant.
Graph Algorithms
is subject of the side by side-side by side mail. Yous volition have to wait two more posts 😉
Grakn World vs Neo4j World
… looks very different, but very like at the same fourth dimension. Grakn way of things are more knowledge oriented and Neo4j feels the graph taste a bit more. Both frameworks are fascinating, and so only one more than question left: who is better ? Upcoming next, the nifty battle of semantics between Grakn and Neo4j 😉
Dear readers, we reached the end of this exhausting article but I won't wave goodbye notwithstanding 😄 Please proceed reading with the Office II and meet me for exploring the fascinating world of semantics. Until then take care and hack happily. 👋
Source: https://towardsdatascience.com/neo4j-vs-grakn-part-i-basics-f2fe3511ce88
0 Response to "What Is the Reading Level of the Neo-4"
Post a Comment